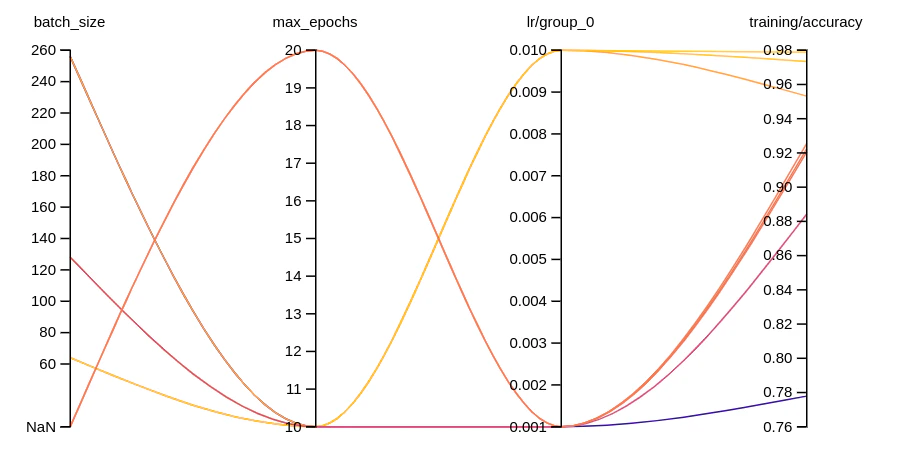
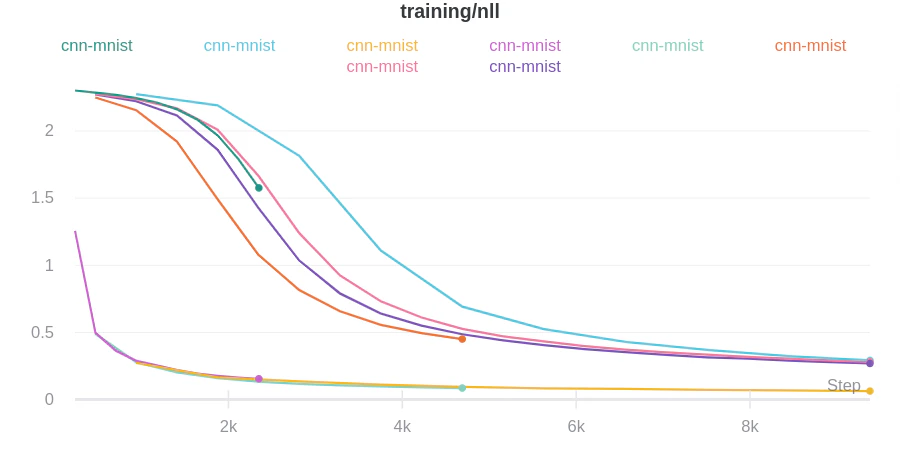
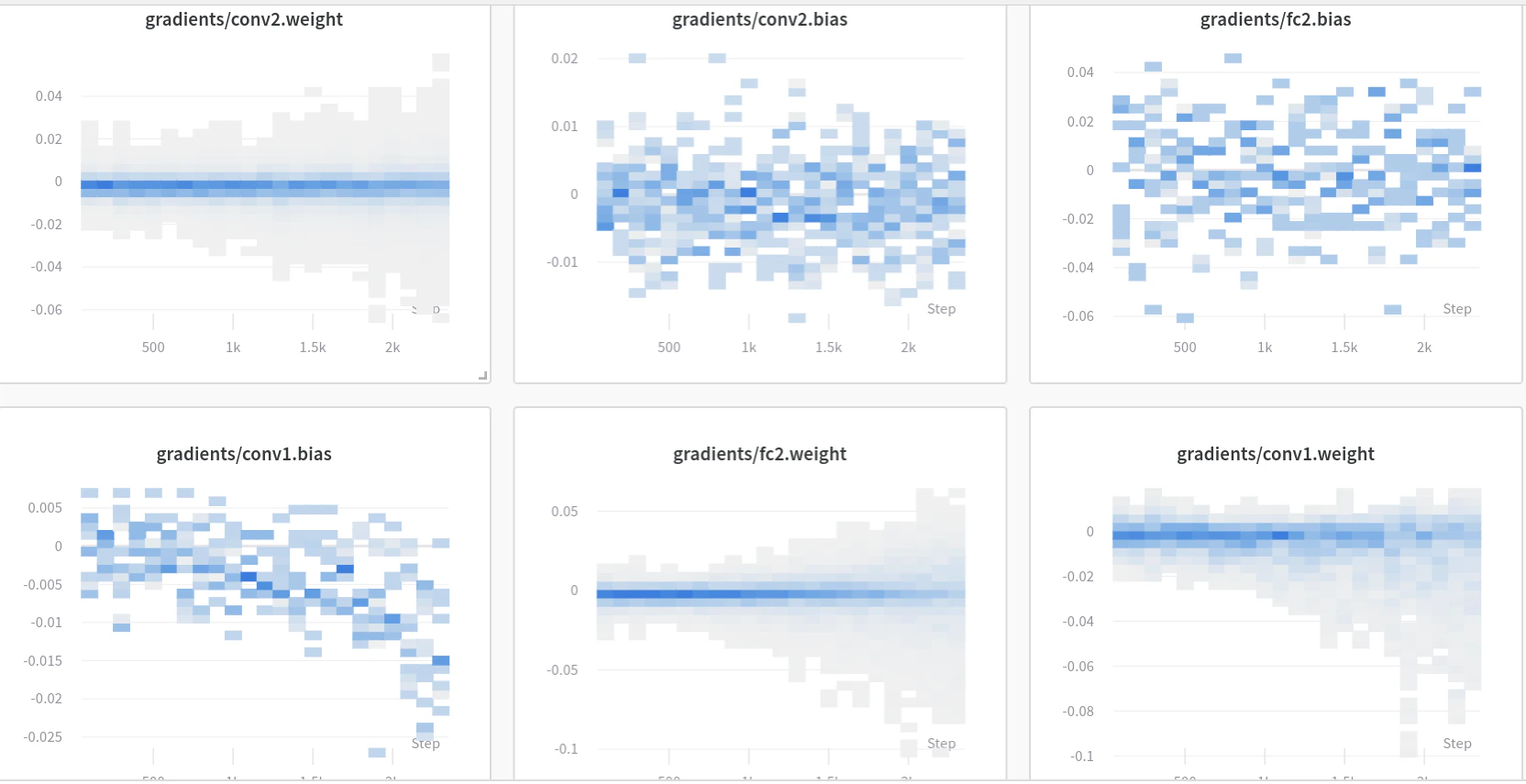
- 이 예시 W&B 리포트 →에서 결과 시각화를 확인해 보세요.
- 이 예시 호스팅 노트북 →에서 직접 코드를 실행해 보세요.
기본 설정
from argparse import ArgumentParser
import wandb
import torch
from torch import nn
from torch.optim import SGD
from torch.utils.data import DataLoader
import torch.nn.functional as F
from torchvision.transforms import Compose, ToTensor, Normalize
from torchvision.datasets import MNIST
from ignite.engine import Events, create_supervised_trainer, create_supervised_evaluator
from ignite.metrics import Accuracy, Loss
from tqdm import tqdm
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=-1)
def get_data_loaders(train_batch_size, val_batch_size):
data_transform = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])
# 트레이닝 및 검증용 MNIST 데이터셋 로드
train_loader = DataLoader(MNIST(download=True, root=".", transform=data_transform, train=True),
batch_size=train_batch_size, shuffle=True)
val_loader = DataLoader(MNIST(download=False, root=".", transform=data_transform, train=False),
batch_size=val_batch_size, shuffle=False)
return train_loader, val_loader
WandBLogger를 사용하는 과정은 모듈식입니다. 먼저 WandBLogger 오브젝트를 생성합니다. 그다음, 메트릭을 자동으로 로그하도록 trainer 또는 evaluator에 연결합니다. 이 예시는 다음을 보여줍니다:
- trainer 오브젝트에 연결되어 트레이닝 손실(loss) 로그.
- evaluator에 연결되어 검증 손실 로그.
- 학습률(learning rate)과 같은 선택적 파라미터 로그.
- 모델 watch(감시).
from ignite.contrib.handlers.wandb_logger import *
def run(train_batch_size, val_batch_size, epochs, lr, momentum, log_interval):
train_loader, val_loader = get_data_loaders(train_batch_size, val_batch_size)
model = Net()
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
optimizer = SGD(model.parameters(), lr=lr, momentum=momentum)
trainer = create_supervised_trainer(model, optimizer, F.nll_loss, device=device)
evaluator = create_supervised_evaluator(model,
metrics={'accuracy': Accuracy(),
'nll': Loss(F.nll_loss)},
device=device)
desc = "ITERATION - loss: {:.2f}"
pbar = tqdm(
initial=0, leave=False, total=len(train_loader),
desc=desc.format(0)
)
# WandBlogger 오브젝트 생성
wandb_logger = WandBLogger(
project="pytorch-ignite-integration",
name="cnn-mnist",
config={"max_epochs": epochs,"batch_size":train_batch_size},
tags=["pytorch-ignite", "mninst"]
)
# 출력 핸들러 연결 (트레이닝 손실 로그)
wandb_logger.attach_output_handler(
trainer,
event_name=Events.ITERATION_COMPLETED,
tag="training",
output_transform=lambda loss: {"loss": loss}
)
# 출력 핸들러 연결 (검증 메트릭 로그)
wandb_logger.attach_output_handler(
evaluator,
event_name=Events.EPOCH_COMPLETED,
tag="training",
metric_names=["nll", "accuracy"],
global_step_transform=lambda *_: trainer.state.iteration,
)
# 옵티마이저 파라미터 핸들러 연결 (학습률 로그)
wandb_logger.attach_opt_params_handler(
trainer,
event_name=Events.ITERATION_STARTED,
optimizer=optimizer,
param_name='lr' # 선택 사항
)
# 모델 그레이디언트 및 파라미터 watch
wandb_logger.watch(model)
EVENTS를 활용하여 터미널에 직접 메트릭을 로그할 수도 있습니다.
@trainer.on(Events.ITERATION_COMPLETED(every=log_interval))
def log_training_loss(engine):
pbar.desc = desc.format(engine.state.output)
pbar.update(log_interval)
@trainer.on(Events.EPOCH_COMPLETED)
def log_training_results(engine):
pbar.refresh()
evaluator.run(train_loader)
metrics = evaluator.state.metrics
avg_accuracy = metrics['accuracy']
avg_nll = metrics['nll']
tqdm.write(
"Training Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f}"
.format(engine.state.epoch, avg_accuracy, avg_nll)
)
@trainer.on(Events.EPOCH_COMPLETED)
def log_validation_results(engine):
evaluator.run(val_loader)
metrics = evaluator.state.metrics
avg_accuracy = metrics['accuracy']
avg_nll = metrics['nll']
tqdm.write(
"Validation Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f}"
.format(engine.state.epoch, avg_accuracy, avg_nll))
pbar.n = pbar.last_print_n = 0
trainer.run(train_loader, max_epochs=epochs)
pbar.close()
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument('--batch_size', type=int, default=64,
help='트레이닝을 위한 입력 배치 크기 (기본값: 64)')
parser.add_argument('--val_batch_size', type=int, default=1000,
help='검증을 위한 입력 배치 크기 (기본값: 1000)')
parser.add_argument('--epochs', type=int, default=10,
help='트레이닝할 에포크 횟수 (기본값: 10)')
parser.add_argument('--lr', type=float, default=0.01,
help='학습률 (기본값: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5,
help='SGD 모멘텀 (기본값: 0.5)')
parser.add_argument('--log_interval', type=int, default=10,
help='트레이닝 상태를 로그하기 전 대기할 배치 수')
args = parser.parse_args()
run(args.batch_size, args.val_batch_size, args.epochs, args.lr, args.momentum, args.log_interval)